


超带宽域成为业内技术探索新领域
2024-11-19 20:15 • By Trading
基础设施技术的进步速度超乎想象。产业链上的每一个环节都需紧密追踪AI驱动的技术革新,并据此进行同步的创新升级。
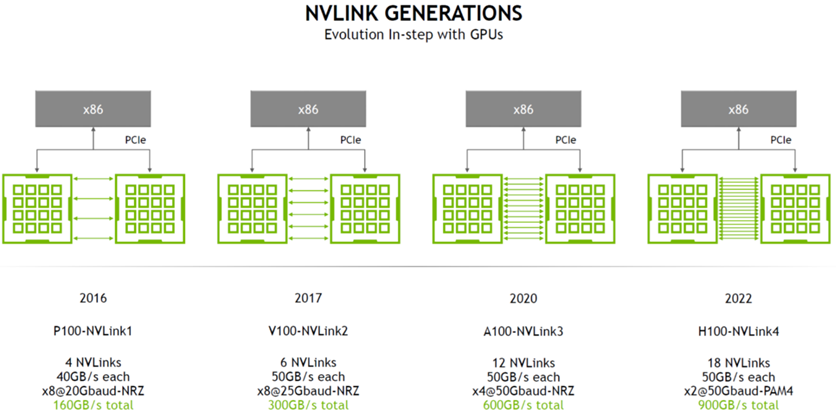
AI网络的Scale-up正在上演一场热烈的军备赛,业界正在呼唤更统一开放的GPU计算卡互联标准,从而打破NVIDIA主导的NVLink以及其所构建的强大的HBD 网络架构的护城河。NVLink 是一种“多节点无损网络”的代表,由一个强大的软件协议组成,通常通过印在计算机板上的多对导线实现,可以让处理器以极高的速度收发共享内存池中的数据。NVLink 的主要设计目的,就是突破PCIe的屏障,达成GPU-GPU及CPU-GPU的片间高效数据交互。
如今讨论Scale-up网络已经不仅提及NVIDIA的NVLink,无论是国际还是国内,行业更多的是在找寻一种更加紧密连接的集群组网,这种紧密耦合所形成的计算系统将有助于推动以GPU为核心的AI网络获得极高的带宽与极低的延迟。
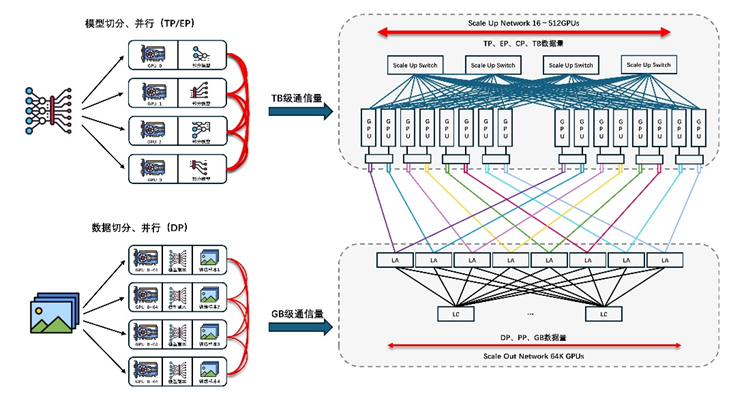
大模型时代,需要更大的模型并行规模,模型并行中Tensor并行或MOE类型的Expert并行都会在GPU之间产生大量的通信,当前典型一机8卡服务器限制了Tensor并行的规模或Expert并行通过机间网络。由此业界开始探索一种以超带宽(HB)互联GPU-GPU的系统,又称HBD(High Bandwidth Domain)。通过构建更大的HBD系统,以Scale-up方式提升系统算力是解决万卡到十万卡集群以上互联挑战的有效途径之一。
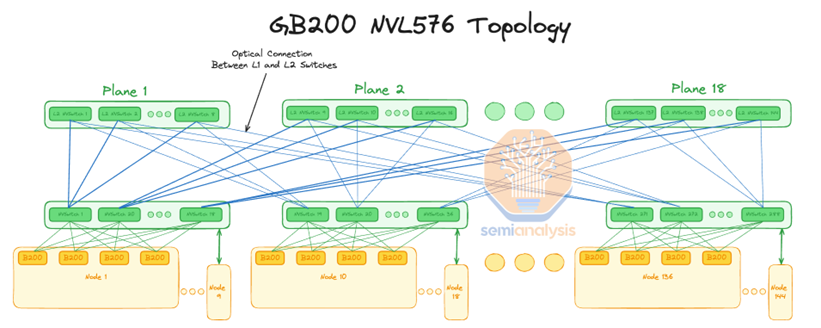
于是NVIDIA的暴力美学再度彰显,以其强大的计算能力继续发挥着引领HBD技术趋势的威力。NVIDIA将HB互联扩展至GPU片间通信之外的领域,将其应用到GPU-CPU/Memory之间的超大带宽互联,例如GH200、GB200产品。借助NVLink-C2C技术的创新,为GPU提供一个超带宽访问CPU/Memory的能力。
据悉,该系统形态的互联已经超过铜缆能够实现的物理连接距离,必须使用光纤连接,这意味着需要花费相当昂贵的成本来实现极高的加速卡带宽。
事实上,超带宽域的稳定运行并非易事,其复杂性不仅体现在网络和计算层面,还包括服务器机架的能耗管理、液冷散热技术、以及机架间光模块与光缆的通信效率等众多挑战。这些问题的解决非一家企业能够独立完成,它需要数据中心产业链的上下游运用集体的智慧来共同突破,以实现高达十万个以上的加速卡的互联。
上个月底,AMD、AWS、Astera Labs、思科、谷歌、惠普企业 (HPE)、英特尔、Meta 和微软等九大董事会成员联合宣布,由其主导的UALink 联盟宣布正式成立,目前已经对行业开放成员邀请。
Ultra Accelerator Link(UALink) 是一种用于GPU加速卡间通信的开放行业标准化互联。UALink 联盟是一个开放的行业标准组织,旨在制定Scale-up互联技术规范,以促进 AI 加速卡(即 GPU)之间的高效互联。该技术规范定义了一种创新的I/O架构,单通道可达200 Gbps传输速率,支持最多1024个AI加速卡互连。相比传统以太网Ethernet)架构,UALink在性能和GPU互联规模上都具有优势,互联规模更是大幅超越NVIDIA NVLink技术。
UALink 1.0 规范可以利用开发和部署了各种加速卡和交换机的推广者成员的经验。
UALink 联盟总裁 Willie Nelson 表示:“UALink 标准定义了数据中心内扩展 AI 系统的高速、低延迟通信。我们鼓励有兴趣的公司以贡献者成员的身份加入,以支持我们的使命:为 AI 工作负载建立开放且高性能的加速卡互联。”预计UALink 1.0规范将在2025年第一季度发布,这与UEC超以太联盟1.0规范的发布节奏同步。
国内AI网络生态圈高度关注Scale-up互联领域的发展,在短短几个月内,以中国移动、阿里云及腾讯云等巨头电信运营商及云厂商分别引领的Scale-up互联生态 OISA、ALink System以及ETH-X超节点等技术规范旨在推动国内智算中心互联生态的快速发展。
由中国移动引领的OISA主要包括四大设计理念,包括“大规模GPU对等互联”、“极致报文格式”、“数据层流控和重传”以及“高效物理传输”,核心思想是为GPU卡间互联提供开放的高带宽、低时延解决方案。此前在6月份的多样性算力产业峰会上,中国移动重点展示了“OISA G1协议”并推出“OISA交换芯片原型”。
OISA G1的设计规格支持128张GPU通过8个Switch芯片互联,任意卡间点对点带宽达到800GB/s,每个Switch芯片支持128个端口,芯片总速率达到51.2T。奇异摩尔目前已经是OISA联盟的成员,公司积极联动运营商、GPU厂商、交换机及服务器领域的优秀生态伙伴、共同推进国内GPU卡间互联标准的建立与实施。
ALS产业生态是业界首个支持UALink成立的产业生态,旨在解决AI网络纵向扩展(Scale-up)中的超高速、超大带宽等技术难题,为下一代智算网络打造开放的、统一的标准规范。在今年9月召开的2024 ODCC开放数据中心大会上, 阿里云联合信通院、奇异摩尔等十多家业界合作伙伴发起了ALS(ALink System,加速器互连系统)开放生态系统。
依托于ODCC(开放数据中心委员会)下设的ALS工作组,生态成员们携手聚焦解决GPU卡间互联系统的行业发展和规范问题,推动Scale-up互连系统标准统一建设,打造下一代AI互连网络软硬件系统。目前,ALS已形成从协议到芯片、从硬件设备到软件平台的系统体系,在ALS-D数据面支持UALink,在ALS-M管控面提供统一接口规范和管控软件平台。
ETH-X超节点联盟选择以太网为基础设施作为GPU超节点项目的首选原型方案。以太网技术(ETH)作为当前最成熟、最开放的网络技术,具有最大交换芯片容量、最高速Serdes技术、200ns交换芯片、最多参与企业的特点,并且已经是当前众多GPU厂商选择的Scale-up接口技术。
据悉,超节点目前已完成Computer-Cable-Switch开放解偶架构设计,保证超节点系统的硬件可以由不同专业领域厂家独立研发生产,并确保了各子系统硬件可集成互通。系统解偶后,各子系统均具有兼容多种GPU芯片、多种Switch芯片及其独立演进的能力,由此充分保证了GPU超节点系统参与厂家的专业性、多样性和开放性。
正如之前我们所提及的加速卡间HBD的挑战,ETH-X以太超节点系统也面临着集成测试、系统运维、协议设计、业务测试等一些列的技术挑战。这一系列的问题需要业界充分协作,共同努力在现有开放生态基础上不断完善、加速GPU超节点系统的成熟与发展。
奇异摩尔自研的网络加速芯粒GPU Link Chiplet——NDSA-G2G,以其极高的灵活性和可扩展性为Scale-up互联生态提供了强有力的支撑。该产品基于可编程众核流式架构,支持用户自定义的协议和处理格式。通过将Chiplet芯粒集成在GPU加速卡内,并利用UCIe D2D接口与GPU互联,NDSA-G2G能够实现高性能的数据流,从而全面加速分布式计算网络。
“据中国IDC圈不完全统计,目前国内不同建设阶段的智算中心项目已超过500个,其中投产运营的项目160个,开工在建项目超过200个。智算中心的建设可谓是如火如荼,其发展关乎到区域经济的发展和产业布局的未来。”
AI网络基础设施作为智算中心的重要基石,直接决定了智算中心的能力、效率、可靠性和安全性。从芯片、交换机、网卡、光模块到其他IT硬件设备,每一个组件都不可或缺,共同构成了一套跨尺度、多层次的复杂系统工程。
奇异摩尔期待未来行业能够拥抱一种开放而统一的物理接口,产业链通过标准制定、软硬件结合等方面的协同最终实现以太网为基础的Scale-up网络和Scale-out网络的融合,从而构建一个更加高效、灵活的智算网络架构,为国内智算中心的发展释放无限可能。
奇异摩尔,成立于2021年初,是一家行业领先的AI网络全栈式互联产品及解决方案提供商。公司依托于先进的高性能RDMA和Chiplet技术,创新性地构建了统一互联架构——Kiwi Fabric,专为超大规模AI计算平台量身打造,以满足其对高性能互联的严苛需求。
我们的产品线丰富而全面,涵盖了面向不同层次互联需求的关键产品,如面向北向Scale out网络的AI原生智能网卡、面向南向Scale up网络的GPU片间互联芯粒、以及面向芯片内算力扩展的2.5D/3D IO Die和UCIe Die2Die IP等。这些产品共同构成了全链路互联解决方案,为AI计算提供了坚实的支撑。
奇异摩尔的核心团队汇聚了来自全球半导体行业巨头如NXPIntel、Broadcom等公司的精英,他们凭借丰富的AI互联产品研发和管理经验,致力于推动技术创新和业务发展。团队拥有超过50个高性能网络及Chiplet量产项目的经验,为公司的产品和服务提供了强有力的技术保障。我们的使命是支持一个更具创造力的芯世界,愿景是让计算变得简单。奇异摩尔以创新为驱动力,技术探索新场景,生态构建新的半导体格局,为高性能AI计算奠定稳固的基石。
原文标题:Kiwi Talks Scale-up 军备赛愈演愈烈,集体对抗英伟达的暴力美学
文章出处:【微信号:奇异摩尔,微信公众号:奇异摩尔】欢迎添加关注!文章转载请注明出处。
,相对于 24G 433 有明显的优势 如下图典型参数2.4GHz433MHz780MHz通信频率该频段有蓝牙、WiFi
窥镜虽然不同于医用内窥镜使用后有水洗、酶洗、消毒等繁杂的清洗程序,但必要的清洁保养是使用者必须做到的。当代制造
专家,至少需要大约10, 000小时的练习与实践,无论是演奏乐器或是编写代码均是如此。按照他的说法,这10,000小时的指导性排练与预演能够真正的重组脑部区域
取得了突破性进展。例如,英国BAE系统公司和伦敦玛丽女王学院研制出一种新型
在德州大学达拉斯分校的部分实验室中,Robert Rennaker博士所提出的“定向可塑”脑部康复研究正处于
`▌ST工业峰会简介科技随“芯”精彩,意法半导体伴您相行!作为拥有18500多项行业领先专利的先驱,意法半导体已经
峰会简介科技随“芯”精彩,意法半导体伴您相行!作为拥有18500多项行业领先专利的先驱,意法半导体已经
▌ST工业峰会简介科技随“芯”精彩,意法半导体伴您相行!作为拥有18500多项行业领先专利的先驱,意法半导体已经
OpenHarmony 发展新机遇 更有全天候互动展区体验一览生态繁荣进展给合作单位、代码贡献者、布道师们提供共同交流的阵地,让大
12月,日本发布新版《防卫计划大纲》《中期防卫力量整备计划》,提出构建“多
有巨大的应用潜力。目前已经有大量的二维铁磁材料被计算预测,包括一些通用的二维材料数据库,包
、研发和实践;应该说还是可以找到亮点的,虽然目前亮光还很小,但是依然值得期待!
与竞争优势 /
xilinx FPGA+Sony LVDS接口图像传感器,已设计出网口输出,现想设计USB3.0输出,有没有什么解决方案?
【RA-Eco-RA2E1-48PIN-V1.0开发板试用】(第三篇)PWM输出+ADC采集
Tags: Trading